Weak Isolation Levels
Database Isolation levels can get confusing and hard to understand. But understanding it is a must to build reliable systems since databases by default provide weaker isolations which do not prevent all concurrency issues.
I wrote this after a joyful read of Martin Kleppmann’s Design Data-Intensive Application. In this write up, I would work on covering the isolation levels and the concurrency problem they solve. For those interested in the detailed read, I refer you to the book.
Building a fault-tolerant system is hard. Many things can go wrong. Transactions in databases have helped in building reliable fault-tolerant systems for decades. Transaction simplifies application development and almost all relational databases support transactions.
Transaction groups several read and write into one logical unit which is executed as one operation. But why do we need to do that? Why cannot we run single operations? We can, but handling all the failure scenarios while preventing the concurrency issues and keeping the group of operations reliable is hard. Transactions in the database make it easy for the application developers to access a database without worrying about error scenarios and concurrency issues.
The well-known acronym ACID helps in understanding the safety guarantees transaction provides. Every database implementation of ACID is slightly different, as ACID is an acronym coined by Joe Hellerstein and it is not an open standard that every database followed. Let’s briefly understand ACID from the perspective of the problems they solve for the application developer.
Atomicity
As said earlier, a transaction is a group of operations, a logical unit that executes together. This logical unit can either succeed or fail when executed. It can never be half complete. That’s atomicity. As coined by Martin in his book, it makes more sense to call it A for Abortability from what safety guarantee it brings. Because of this property, application developers can safely abort transactions on errors and have all changes from that transaction discarded safely. On abort, the application developers can safely retry transactions and there is no worry of duplicates as the guarantee ensures no changes happened in the earlier transaction. This makes things easy for the application.
Consistency
Joe Hellerstein coined ACID, and has remarked that C in ACID was “tossed to make the acronym work”. Consistency means certain invariants about your data should always be true and writes should preserve the invariants. This is true for some invariants like foreign key constraints, unique constraints, but in general, the application is responsible for defining its transaction correctly so that the invariants are obeyed and consistency is preserved. So it is right to say that consistency is an application responsibility and is not a safety guarantee provided by the database. C for nothing? People who do not remember what was C in ACID, do not worry it was nothing!
Durability
D for Durability guarantee means data written in successful transactions will never get lost. That’s the guarantee. But let’s consume this information with more context:
- In a single node database, durability means the data has been written to nonvolatile storage as a Hard disk or SSD. Write-Ahead Log in databases allows data recovery in case of disk corruption.
- In a replicated database, durability means the data has been copied to some number of nodes and the guarantee here is provided by waiting for replication to other nodes complete. Write is successful if the data has been successfully replicated to N nodes.
- No Durability can be guaranteed if all the hard disks and backups are destroyed or if the Meteor hits the Earth! There is no absolute guarantee.
Isolation
There is no problem if multiple running transactions are accessing different data in the database. But if they access the same data in the database, then concurrency problems, i.e. race conditions, may arise. I for Isolation is the guarantee that transactions are completely isolated from each other when executing concurrently. For a transaction, it is like it is the only executing transaction in the database. The guarantee provided by the database here is the result after multiple concurrently ran transactions finish is the same if the transactions were executed serially one by one (Strongest isolation level).
In real life, executing transactions serially is a tremendous performance hit, hence most of the database gives weaker isolation levels as defaults. The weaker isolation levels protect us from some concurrency issues, but not all. So, an application developer needs to understand them. Let’s understand the weaker isolation levels and the concurrency issues they solve.
Level 0 to above are in order of weaker to stronger isolation order.
Level 0: Read Committed
Most basic isolation level and it solves the Dirty Read and Dirty Write phenomena:
Dirty Read: When a transaction reads data that has not been committed.
Dirty Write: When a transaction overwrites the value written by an ongoing transaction.
Problems with Dirty Read: Listing down a few unintended outcomes that can occur.
- If a transaction updates many objects in a database and other transactions saw only some changes, then the other transaction can take incorrect decisions and the database will look inconsistent to it. An excellent example to explain is: Say, Alice has two bank accounts in a Bank with 500Rs in each and she requested the bank to transfer 100Rs from one account to another.
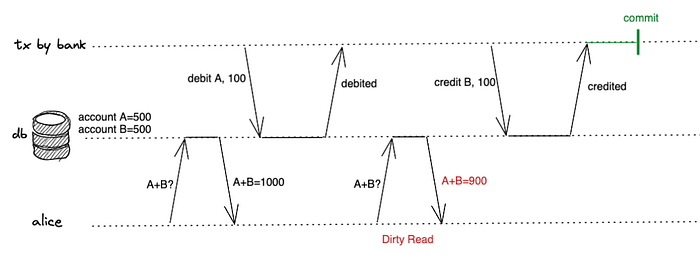
2. If a transaction reads un-committed data and later that data was rolled back it can become really confusing for the application and cause bugs that are hard to trace and fix.
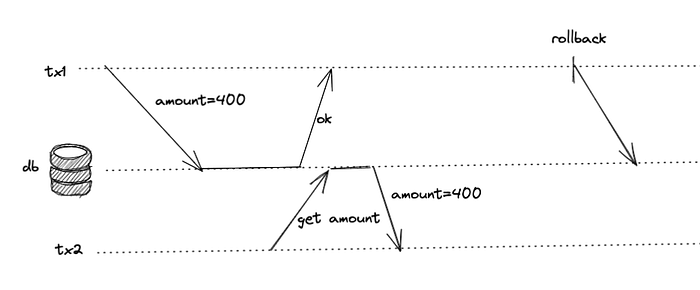
Problems with Dirty Write
Last write wins causing intermingled transactions making a mess.
Read-Commited isolation level prevents the above problems. You get to read only the committed data from the database and you can only overwrite the last committed data.
How does the database implement Read Committed?
- Row Level Write Locks are used to lock the data in a transaction. Other transactions have to wait for the lock to release before they can change the same row. This is how dirty writes are prevented!

- No read-locks, databases can remember old values: To prevent dirty read databases, do not use read locks because a single long-running transaction can block many read-only transactions to wait until the long-running transaction finishes. So, if a transaction holds the write lock on data, the database remembers both the old and new values of that data. It gives back the old value to all the transactions that want to read that data. This Is how dirty reads are prevented!

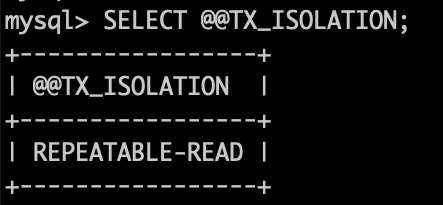
Level 1: Repeatable Read / Snapshot Isolation
This is the default isolation level for many relational databases.
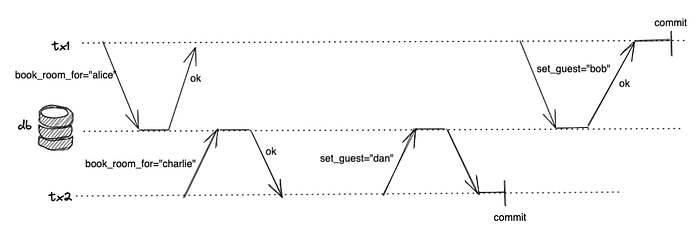
Read Committed solved a few of the concurrency problems/phenomena. But there are more concurrency issues that can occur. Let’s look at them:
Read Skew
The transaction can read different objects at different times, causing a read skew. This is clearly understood with an example: say Alice has two accounts A and B in a Bank and it is a joint account with Bob. Bob made a transfer from account A to B without informing Alice and Alice's balance may look inconsistent as she did not expect the total balance to drop which has not dropped but it looked to Alice as it did(she saw 900 in total). This anomaly is known as non-repeatable Read or Read-Skew.

Wait! How is it different from Dirty Read? It is not a dirty read as both the reads of Alice are from committed data. It was just the timing of the read causing the problem. This timing anomaly is expected in a Read Committed Isolation level.
Solution: Repeatable Read or Snapshot Isolation level solves this by giving each transaction a point in time consistent snapshot of the database. The point is time is the start of the transaction. The transaction during the execution cannot see any other data or changes that were committed after it started. Almost all relational databases provide this isolation level.
How does the database implement Snapshot Isolation?
- Row Level Write Locks: This is exactly how Read Committed Isolation level does it. A transaction acquires the lock and then updates the data object, blocking and making other transactions wait to write the same data object.

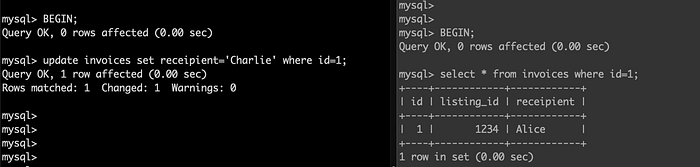
- No read-locks, databases can remember old values: Yes this is the same as Read-Committed Isolation’s implementation, the only thing is database here needs to remember not just 2 values but many versions of the data object. Since each transaction will see its own version for the read. This technique is known as Multi-Version Concurrency Control (MVCC).
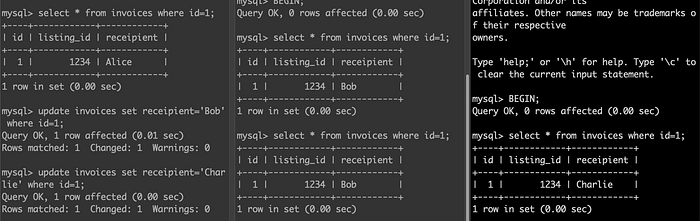
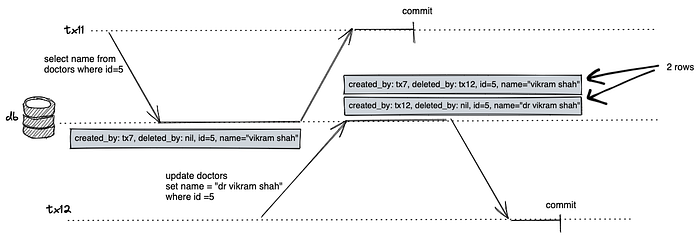
MVCC Implementation
- Unique ever-increasing transaction ID for each transaction. tx1, tx2, tx3,…
2. Table Row gets the following extra metadata fields:
- created_by: contains the transaction id which caused the change.
- deleted_by: contains transaction id that requested deletion. deletion happens async by the garbage collection process when it is sure no tx can access the deleted data.
3. The update is translated into a delete and create. So in case of updates, 2 rows are created: one with deleted_by updated with tx id and the other row with created_by updated with tx id.
4. Visibility rules: Reads use the transaction IDs to determine which database object it can see and what is hidden.
There are many other types of concurrency problems that can still occur, and there is a variety of solutions made to solve them.
Click here to go to the 2nd part of this blog.

